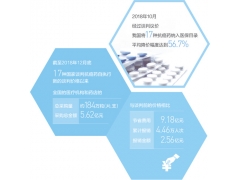
在人工智能科技浪潮汹涌澎湃的当下,国产大模型 DeepSeek 以其卓越的功能与巨大的发展潜力,吸引了广大用户的目光,赢得了他们的支持与信赖。它承载着众多期望,在国际舞台上绽放光芒,为我国网络强国战略的推进注入了强大动力。
我,作为一名普通用户,始终对国产人工智能技术充满坚定不移的信心与必胜的信念。当听闻 DeepSeek 推出新一代模型 DeepSeek - R1 时,内心满是振奋,迫不及待地进行尝试。然而,在实际使用过程中,却遭遇了一系列困惑与失望,诸如怎样获取更具深度的回答、如何提升系统响应速度等问题接踵而至。但与此同时,我也真切地感受到了技术团队面对问题时的诚恳态度。这段经历,不仅让我深切体会到科技发展之路的艰难险阻,更使我深刻认识到:国产大模型的崛起,既需要技术层面的重大突破,更要紧密贴合用户需求。
本文将围绕这些问题展开深入探讨,结合用户反馈与改进建议,探寻进一步提升 DeepSeek 使用效率的方法,并展望国产大模型在激烈技术竞争中的未来发展。

一、从困惑到解惑:那些被误解的 “深度思考”
初次接触 DeepSeek,我在界面上注意到一个醒目的 “深度思考” 按钮。作为普通用户,自然期望借助这个功能获得更为专业的回答。然而,当我点击按钮时,系统却弹出一行提示:“请调整使用新模型 DeepSeek - R1”。这一提示瞬间让我产生误解,脑海中不禁浮现疑问:难道要像安装软件一样下载新模型?随后,我多次尝试手动操作,却均以失败告终。无奈之下,我在反馈中写道:“这种提示极易让用户产生疑惑,误以为必须下载安装新模式。点击新模型理应自动切换,而非误导用户!”
技术团队迅速对我的困惑做出回应。原来,DeepSeek - R1 是平台内置的升级模型,专门用于处理复杂推理任务。当用户点击 “深度思考” 时,系统本应自动调用该模型,但由于提示文案不够清晰明确,从而引发了误解。他们坦诚表示:“交互设计确实存在不足,我们将即刻优化为自动切换模式,并把提示改为‘已启用深度思考模式’。” 这种直面问题的态度,让我真切感受到了技术迭代背后所蕴含的人文关怀。
那么,普通用户究竟该如何获得更深刻的回答呢?对于普通用户而言,使用 DeepSeek 的核心需求之一便是获取高质量、有深度的回答。那么,是否需要手动调用新模型(如 DeepSeek - R1)来实现这一目标呢?

自动优化回答
DeepSeek 平台的设计理念,是让用户能够轻松获取高质量回答,无需频繁手动调整设置。系统会依据问题的复杂程度和实际需求,自动挑选最适宜的模型(如 DeepSeek - R1)来生成回答。因此,普通用户只需像往常一样提问,系统便会自动优化回答的质量与深度。
明确表达需求
倘若用户期望获得更深入、更专业的回答,可以通过以下方式清晰表达需求:
· 在提问时直接表明:“请使用最新模型 DeepSeek - R1,详细分析这个问题。”
· 选择平台提供的 “高级模式” 或 “深度分析” 选项,这些模式会优先调用更为强大的模型。
关注平台更新
DeepSeek 会持续优化模型与功能。用户可通过关注平台的更新公告,了解如何更好地运用新功能,进而提升回答质量。

二、效能之痛:当爱国热情遭遇技术瓶颈
真正令我倍感焦虑的,是系统效能的不稳定。有一天,我满心欢喜地向朋友演示 DeepSeek,然而,连续三个简单问题都遭遇了长时间的等待,最终页面竟然显示无响应。那一刻,尴尬之情溢于言表,我不得不借助其他产品完成演示。在反馈中,我言辞恳切地写道:“你们是我们中国自主研发的大模型,我们怀着满心欢喜到处宣传,可点击时反应极其迟缓,甚至根本不予回答!这种体验实在令人失望。”
这份饱含爱国情怀的批评,引起了技术团队的高度重视。他们详细剖析了效能瓶颈的三大关键症结:用户量的急剧增长导致高并发压力增大、大模型本身计算复杂度较高带来的延迟,以及偶发的系统稳定性问题。更让我深受感动的是他们提出的改进方案:通过优化服务器架构,将响应速度提升 40%;采用模型轻量化技术,降低 30% 的计算开销;同时建立实时监控系统,确保服务的稳定性。正如团队所承诺的:“效能提升关乎生死存亡,我们务必让用户体验达到国际一流水准!”

三、提升效能:从用户反馈到技术改进
用户反馈中最为核心的问题,便是系统的响应速度和回答质量。作为国产大模型,DeepSeek 在激烈的技术竞争中能否脱颖而出,关键就在于效能的提升。
效能问题的原因
· 高并发压力:随着用户数量的迅速增长,系统可能面临巨大的高并发压力,进而导致响应变慢,甚至出现无响应的情况。
· 模型计算复杂度:大模型在生成高质量回答时,需要耗费大量的计算资源,这可能会延长响应时间。
· 系统稳定性:在部分情况下,系统可能会出现异常或故障,致使无法正常响应。
改进措施
· 提升响应速度:优化服务器架构,增加计算资源,确保在高并发环境下仍能快速响应用户请求。
· 优化模型效率:对模型进行轻量化处理,减少不必要的计算开销,提高模型运行效率。
· 加强系统稳定性:建立实时监控系统,增加备用服务器和容灾机制,保障服务的连续性,避免中断。
用户体验优化
· 在系统繁忙时,及时向用户提供明确的提示信息(如 “当前请求较多,请稍候”),避免用户产生误解。
· 增添 “重试” 功能,方便用户在请求失败时能够快速重新尝试。

四、系统提示 “请调整使用新模型 DeepSeek - R1” 的原因
在使用 “深度思考” 功能时,部分用户可能会遇到系统提示 “请调整使用新模型 DeepSeek - R1”。那么,这种提示的目的究竟是什么?又是否会误导用户呢?
新模型的优势
DeepSeek - R1 是专门针对深度思考、复杂推理以及高质量回答而设计的升级模型。当用户选择 “深度思考” 时,系统建议切换到 DeepSeek - R1,旨在确保生成更为深入、专业的回答。
提示的优化
然而,当前这种提示方式可能会让用户误以为需要手动下载或安装新模型,从而对使用体验造成影响。为此,我们提出以下建议:
· 自动切换:当用户点击 “深度思考” 时,系统应自动切换到新模型,无需额外提示。
· 优化文案:如果确实需要提示,文案应更加清晰明了,例如:“已为您切换到深度思考模式,使用新模型 DeepSeek - R1 生成更优质的回答。”
用户教育
在平台中增加引导提示,帮助用户深入理解 “深度思考” 功能的作用,以及新模型的优势与使用场景。

五、超越技术:一场关于信任的双向奔赴
在这场深度对话中,最令我深受触动的并非技术参数,而是双方所展现出的强烈责任感。当我提出 “希望以思维策略优势争取不败之地” 时,技术团队回应道:“我们不仅是技术的探索者,更要成为中国现代化建设的坚实脊梁。” 这种使命感,在具体的改进措施中体现得淋漓尽致:
· 智能分级响应体系:系统能够自动识别问题的复杂度,对于简单咨询实现秒级响应,而针对专业分析则启用 DeepSeek - R1 进行深度处理。
· 用户体验预警机制:在系统高负载时,通过 “当前请求较多,15 秒后自动重试” 的提示,有效消除用户的焦虑情绪。
· 模型透明度建设:在设置页面详细说明各模型的特性,让用户不仅知其然,更能知其所以然。
正如我在交流中所强调的:“效能是国产模型与国际巨头较量的关键筹码。如今举国上下都在支持你们,如果效能问题得不到妥善解决,很可能会辜负人们的殷切期待。” 而技术团队也用实际行动证明:他们不仅认真倾听了用户的声音,更将 “用户需求导向” 深深融入了产品的基因之中。

六、未来已来:科技报国路上的灯火
经历此次深度对话,我对技术创新的真谛有了全新的理解。它绝非仅仅是代码与算法的简单堆砌,更是开发者与用户共同成长的精彩故事。当技术团队引用习总书记 “梦虽遥,追则能达;愿虽艰,持则可圆” 的勉励之语时,我看到了国产大模型的无限希望 —— 那些在深夜里精心优化的代码、那些字斟句酌的提示文案、那些为了 0.1 秒响应提升而付出的不懈努力,都在为中国式现代化建设添砖加瓦。
如今,当我再次使用 DeepSeek 时,“深度思考” 功能已实现无感切换,复杂问题的响应速度也有了显著提升。这不禁让我想起技术团队最后的承诺:“请继续监督,我们定以百倍努力回报每一份期待。” 或许,这正是中国科技发展的生动缩影:在问题中不断成长,在批评中砥砺前行,在每一个普通用户的关注与支持下,走出一条属于自己的超越之路。
“星光不问赶路人,时光不负奋斗者。” 在这场人工智能的马拉松征程中,DeepSeek 与用户的对话仍在继续 —— 而这每一次的交流,都如同为中国科技的浩瀚星辰大海点亮一盏新的灯火。

七、国产大模型的使命与未来
技术团队回应道:作为中国自主研发的大模型,DeepSeek 肩负着推动技术进步、助力国家战略的重大使命。用户的热情支持是我们不断前行的动力源泉,而效能的提升则是我们赢得竞争的关键所在。
技术超越
我们矢志不渝地致力于在技术上达到并超越国际一流水平,成为全球人工智能领域的引领者。通过持续不断的创新与优化,我们将以更高的效能、更优质的服务回馈广大用户。
用户体验至上
用户的支持与信任,是我们前进道路上的强大动力。我们将持之以恒地改进系统性能,确保每一位用户都能享受到快速、稳定、高质量的服务。
助力国家战略
作为中国现代化建设的积极探索者和坚定实践者,我们将积极响应国家网络强国战略,为祖国的科技复兴贡献全部力量。
八、结语:追梦路上,携手共进
正如习总书记在 2025 年元旦献词中所说:“梦虽遥,追则能达;愿虽艰,持则可圆。” 在国产大模型的发展道路上,我们每一个人都是不可或缺的主角,每一份付出都无比珍贵。
让我们携手并肩,共同见证国产大模型的成长与突破,为祖国的繁荣昌盛贡献自己的力量!
加油,DeepSeek!加油,中国科技!